
- Moonshot AI’s Kimi K2 Thinking outperformed GPT-5 and Claude 4.5 across key reasoning and coding benchmarks.
- The one-trillion-parameter MoE model activates 32B per inference and supports 256k-token context windows.
- Fully open-source under a Modified MIT License, K2 Thinking costs up to 10x less than GPT-5 while matching or exceeding its performance.
Moonshot AI, the Chinese startup backed by Alibaba, has unleashed a shockwave across the global AI industry with the release of its Kimi K2 Thinking model, a trillion-parameter behemoth that has outperformed OpenAI’s GPT-5 and Anthropic’s Claude 4.5 Sonnet across key reasoning and coding benchmarks.
Launched on November 6, Kimi K2 Thinking achieved state-of-the-art results, scoring 44.9% on Humanity’s Last Exam, 60.2% on the BrowseComp web reasoning benchmark, and 71.3% on SWE-Bench Verified, cementing its lead over both U.S. and Chinese peers. Built as a Mixture-of-Experts (MoE) model, it activates 32 billion parameters per inference from a trillion-parameter total and supports a 256,000-token context window, enabling deep reasoning over extended conversations.
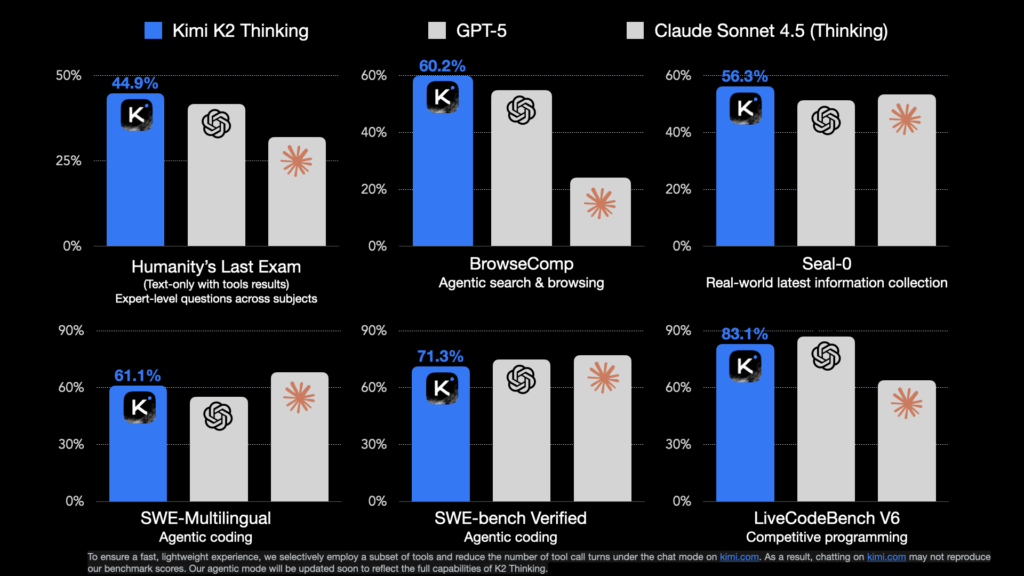
Unlike proprietary systems, K2 Thinking is fully open-source under a Modified MIT License, allowing unrestricted commercial use with a light attribution clause for massive-scale deployments. Its transparent reasoning design exposes each logical step in outputs, helping users verify multi-stage problem-solving in real time, a rarity among closed models.
Despite its massive scale, the model’s runtime efficiency is exceptional: it costs just $0.15 per million tokens (cache hits) and $2.50 for output, nearly ten times cheaper than GPT-5’s reported pricing. Moonshot AI claims it can perform 200–300 sequential tool calls autonomously, marking a new high for “agentic” reasoning systems that can plan, execute, and self-correct tasks without human guidance.
Benchmarks reveal K2 Thinking not only outpaces GPT-5 (54.9%) and Claude 4.5 (24.1%) in BrowseComp, but also matches or exceeds GPT-5 in technical reasoning and coding domains. This milestone effectively collapses the performance gap between open-weight models and frontier proprietary systems.
K2 Thinking’s rise comes as major U.S. AI firms face growing scrutiny over $1.4 trillion in cumulative AI infrastructure spending. With open-weight systems like Moonshot’s K2 and MiniMax-M2 achieving near or superior results at a fraction of the cost, the economics of “bigger is better” AI are now being fundamentally questioned.
For enterprises, this marks a paradigm shift. High-end reasoning and coding performance no longer requires billion-dollar data centers; it’s now available, freely and openly, from China’s rapidly evolving AI ecosystem.
Editorial Note: This news article has been written with assistance from AI. Edited & fact-checked by the Editorial Team.
Interested in advertising with CIM? Talk to us!

Clarkson University’s Rex AI Framework Targets Sharper Image Editing and Drug Discovery
Clarkson University researchers built Rex, an AI framework that lets diffusion and flow-matching models reverse their own process with far less error. The work was accepted as an Oral at ICML 2026, the top 0.7% of submissions.

SuperAI Singapore 2026: Key Talks Defining the State of AI in 2026
SuperAI Singapore 2026 gathered 10,000 attendees at Marina Bay Sands on June 10-11. Benedict Evans warned of financial gravity in the AI boom, Exa's Will Bryk mapped the rise of agent search, Max Tegmark pushed a pro-human safety case, and Cerebras made the case for faster inference.

Your AI Agents Are Prisoners, and Nobody’s Talking About It
Cloud providers built walls around AI agents, locking them into closed credit systems. The x402 protocol, now under the Linux Foundation with AWS, Visa, and Google backing, lets agents own wallets and transact on open rails. A look at why machine commerce may already be inevitable.